بهترین گزینه های ChatGPT (طبق ChatGPT)
ChatGPT به سرعت تبدیل به یکی از عزیزان هوش مصنوعی مولد شده است، اما به سختی تنها بازیکن در بازی است. علاوه بر تمام ابزارهای هوش مصنوعی دیگر که کارهایی مانند تولید تصویر را انجام می دهند، تعدادی رقیب مستقیم برای ChatGPT وجود دارد – یا من فکر می کردم.
چرا از ChatGPT در مورد آن سؤال نمی کنید؟ این دقیقاً همان کاری است که من برای دریافت این لیست انجام دادم، به امید اینکه گزینههایی برای کسانی که با اعلامیههای «ظرفیت ناکافی» مواجه هستند یا دیگرانی که فقط میخواهند چیز جدیدی را امتحان کنند، پیدا کنم. همه آنها به اندازه ChatGPT در دسترس عموم نیستند، اما طبق گفته ChatGPT، اینها بهترین جایگزین ها هستند.
BERT توسط Google
BERT (نمایش رمزگذار دوطرفه از Transformers) یک مدل یادگیری ماشینی است که توسط Google توسعه یافته است. بسیاری از نتایج ChatGPT به پروژههای Google اشاره میکنند که بعداً در این لیست خواهید دید.
BERT به دلیل قابلیتهای پردازش زبان طبیعی (NLP) مانند پاسخگویی به سؤال و تحلیل احساسات شناخته شده است. این کتاب از BookCorpus و ویکیپدیا انگلیسی بهعنوان مدلهای مرجع برای پیشآموزش استفاده کرد و بهترتیب ۸۰۰ میلیون و ۲.۵ میلیارد کلمه را آموخت.
BERT برای اولین بار به عنوان یک پروژه تحقیقاتی منبع باز و مقاله دانشگاهی در اکتبر 2018 معرفی شد. از آن زمان این فناوری در جستجوی گوگل پیاده سازی شده است. ادبیات اولیه BERT آن را با ChatGPT OpenAI در نوامبر 2018 مقایسه کرد و اشاره کرد که فناوری Google عمیقاً دو طرفه است که به پیشبینی متن دریافتی کمک میکند. در همین حال، OpenAI GPT یک طرفه است و فقط می تواند به درخواست های پیچیده پاسخ دهد.
مینا از گوگل
مینا یک چت بات است که گوگل در ژانویه 2020 با قابلیت مکالمه به صورت انسانی معرفی کرد. نمونههایی از ویژگیهای آن عبارتند از مکالمات ساده که شامل جوکها و جناسهای جالبی میشود، مانند پیشنهاد مینا مبنی بر اینکه گاوها در دانشگاه هاروارد «علوم گاوداری» بخوانند.
به عنوان یک جایگزین مستقیم برای GPT-2 OpenAI، Meena توانایی پردازش 8.5 برابر بیشتر از رقیب خود در آن زمان را داشت. شبکه عصبی آن از 2.6 پارامتر تشکیل شده است و بر روی مکالمات عمومی در رسانه های اجتماعی آموزش داده شده است. Meena همچنین امتیاز سنجش حساسیت و میانگین ویژگی (SSA) 79 درصد را دریافت کرد که آن را به یکی از باهوش ترین چت ربات های زمان خود تبدیل کرد.
کد Meena در GitHub موجود است.
RoBERTa از فیس بوک
RoBERTa (رویکرد پیشآموزشی بهینهسازی قوی BERT) نسخه پیشرفته دیگری از BERT اصلی است که فیسبوک در جولای 2019 اعلام کرد.
فیس بوک این مدل NLP را با منبع داده بزرگتر به عنوان یک مدل قبل از آموزش ساخت. RoBERTa از CommonCrawl (CC-News) استفاده می کند که شامل 63 میلیون مقاله خبری انگلیسی است که بین سپتامبر 2016 و فوریه 2019 تولید شده است، به عنوان مجموعه داده 76 گیگابایتی خود. به گفته فیس بوک، در مقایسه، BERT اصلی از 16 گیگابایت داده بین مجموعه داده های ویکی پدیا انگلیسی و BookCorpus خود استفاده کرده است.
طبق یک مطالعه فیسبوک، RoBERTa به XLNet، BERT را در مجموعهای از مجموعه دادههای معیار شکست داد. برای به دست آوردن این نتایج، این شرکت نه تنها از یک منبع داده بزرگتر استفاده می کند، بلکه مدل خود را برای مدت زمان طولانی تری از قبل آموزش می دهد.
فیس بوک RoBERTa را در سپتامبر 2019 منبع باز کرد و کد آن در GitHub برای آزمایش جامعه در دسترس است.
VentureBeat همچنین GPT-2 را در میان سیستم های هوش مصنوعی در حال ظهور در این مدت ذکر کرد.
XLNet توسط گوگل
XLNET یک مدل زبان اتورگرسیو مبتنی بر ترانسفورماتور است که توسط تیمی از محققان در Google Brain و دانشگاه کارنگی ملون توسعه یافته است. این مدل اساساً یک BERT پیشرفتهتر است و برای اولین بار در ژوئن 2019 ارائه شد. گروه دریافتند که XLNet حداقل 16٪ کارآمدتر از BERT اصلی است که در سال 2018 معرفی شد و در آزمایشی از 20 کار NLP بر BERT را شکست داد.
از آنجایی که XLNet و BERT از نشانههای «ماسک شده» برای پیشبینی متن پنهان استفاده میکنند، XLNet با سرعت بخشیدن به بخش پیشبینی فرآیند، کارایی را بهبود میبخشد. به عنوان مثال، آیشواریا سرینیواسان، دانشمند داده آمازون الکسا، توضیح داد که XLNet قبل از پیشبینی اینکه عبارت «یورک» نیز با آن واژه مرتبط است، توانست کلمه «جدید» را با عبارت «شهر است» شناسایی کند. در همین حال، BERT باید کلمات “New” و “York” را جداگانه شناسایی کند و سپس آنها را به عنوان مثال به اصطلاح “شهر است” متصل کند.
لازم به ذکر است که GPT و GPT-2 نیز در این توضیح دهنده 2019 به عنوان نمونه های دیگر از مدل های زبان اتورگرسیو ذکر شده اند.
کد XLNet و مدل های از پیش آموزش دیده در GitHub موجود است. این مدل در جامعه تحقیقاتی NLP به خوبی شناخته شده است.
DialoGPT از Microsoft Research
DialoGPT (Dialogue Generative Pre-trained Transformer) یک مدل زبان اتورگرسیو است که در نوامبر 2019 توسط Microsoft Research معرفی شد. با شباهت به GPT-2، این مدل برای ایجاد مکالمه انسانی از قبل آموزش داده شده بود. با این حال، منبع اصلی اطلاعات او 147 میلیون دیالوگ چند نوبتی بود که از تاپیک های Reddit جمع آوری شده بود.
Cobus Grayling، Chief Evangelist HumanFirst به موفقیت خود در استقرار DialoGPT در سرویس پیام رسان تلگرام اشاره کرد تا مدل چت بات را زنده کند. او افزود که استفاده از خدمات وب آمازون و آمازون SageMaker می تواند به تنظیم دقیق کد کمک کند.
کد DialoGPT در GitHub موجود است.
ALBERT توسط گوگل
ALBERT (A Lite BERT) یک نسخه کوتاه شده از BERT اصلی است و توسط گوگل در دسامبر 2019 توسعه یافته است.
با ALBERT، گوگل تعداد پارامترهای مجاز در مدل را با معرفی پارامترهای “جاسازی لایه پنهان” محدود کرد.

این نه تنها در مدل BERT، بلکه در XLNet و RoBERTa نیز بهبود یافته است، زیرا ALBERT میتواند در همان مجموعه اطلاعات بزرگتر مورد استفاده برای دو مدل جدیدتر آموزش ببیند، در حالی که به پارامترهای کوچکتر پایبند باشد. اساسا، ALBERT فقط با پارامترهای لازم برای عملکردهای خود کار می کند، که عملکرد و دقت را افزایش می دهد. گوگل بیان میکند که دریافته است که ALBERT در 12 معیار NLP، از جمله معیار درک مطلب شبیه SAT، بهتر از BERT عمل میکند.
اگرچه با نام ذکر نشده است، GPT در تصاویر ALBERT در وبلاگ Google Research گنجانده شده است.
گوگل ALBERT را به عنوان منبع باز در ژانویه 2020 منتشر کرد و در بالای TensorFlow گوگل پیاده سازی شد. کد در GitHub موجود است.
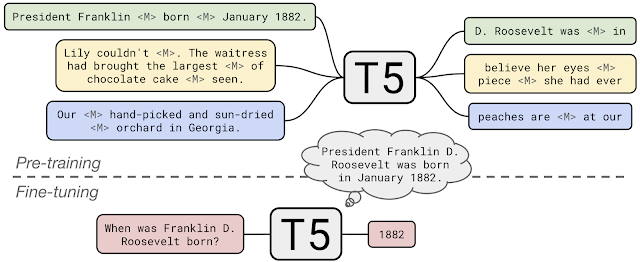
T5 توسط گوگل
CTRL از Salesforce

GShard از گوگل
GShard یک مدل غول پیکر ترجمه زبان است که گوگل در ژوئن 2020 برای مقیاس شبکه های عصبی معرفی کرد. این مدل شامل 600 میلیارد پارامتر است که امکان آموزش مجموعه داده های بزرگ را به طور همزمان فراهم می کند. GShard به ویژه در ترجمه زبان ماهر است و برای ترجمه 100 زبان به انگلیسی در چهار روز آموزش دیده است.
Blender توسط Facebook AI Research
Blender یک چت بات منبع باز است که در آوریل 2020 توسط Facebook AI Research معرفی شد. این ربات چت در مقایسه با مدلهای رقیب، مهارتهای مکالمهای را بهبود میبخشد، با توانایی ارائه نکات گفتگوی جذاب، گوش دادن و نشان دادن درک نظرات شریک خود، و نشان دادن همدلی و شخصیت.

Blender با چت بات Google Meena مقایسه شده است، که به نوبه خود با GPT-2 OpenAI مقایسه شده است.
کد Blender در Parl.ai موجود است.
پگاسوس توسط گوگل
Pegasus یک مدل پردازش زبان طبیعی است که توسط گوگل در دسامبر 2019 معرفی شد. Pegasus را می توان برای تولید خلاصه آموزش داد و مانند مدل های دیگر مانند BERT، GPT-2، RoBERTa، XLNet، ALBERT و T5، می تواند به خوبی تنظیم شود. وظایف خاص. Pegasus برای اثربخشی آن در خلاصه کردن اخبار، علم، داستانها، دستورالعملها، ایمیلها، پتنتها و لوایح قانونی در مقایسه با انسانها آزمایش شده است.
کد Pegasus در GitHub موجود است.
توصیه های سردبیران